【ECCV2018 論文メモ#1】Learning to Anonymize Faces for Privacy Preserving Action Detection
ECCV2018まで1ヶ月を切ったので興味がある論文のメモを残していく。(
1日1本のペースで空き時間を使ってやっていきたい。(多分無理だ)
今回の論文と出典
Learning to Anonymize Faces for Privacy Preserving Action Detection
https://arxiv.org/abs/1803.11556
著者
Zhongzheng Ren, Yong Jae Lee, Michael S. Ryoo
内容
- アクション検出を維持しながらプライバシーのための顔情報匿名化の学習
- アクション検出とは、「電話をする、歯を磨く、化粧をする」などを指す
- 顔情報匿名化とは、既存手法では、顔へのBlurやMask、Noiseなどを指す

(既存匿名化手法例 / 上図:出典より抜粋)
- 提案手法では、より自然にシーンやアクションを維持したピクセルレベルの匿名化が可能

(左顔は提案手法匿名化前、右顔は提案手法匿名化後 / 上図:出典より抜粋)
- GANの仕組みをベースに敵対的学習する
- 「異なる見た目の修正顔を作るGenerator(Modifier)」
- 「修正顔であるにも関わらず正しく個人識別できるように学習するDiscriminator」
- 更にマルチタスク学習として、ActionDetectionを統合して精度を高めている
詳細
- モデルは下図の通り

(モデル / 上図:出典より抜粋)
と
は、顔画像 (
- Action Detectionは、Faster RCNN
- Face Detectionは、SSH[29]
- Face Recognitionは、Sphereface[26]
- Generatorは、個人識別精度を最小化したい
- InputとOutputで別人にしたいので
- Discriminatorは、個人識別精度を最大化したい
- (修正済みだろうと)どんな入力が来ても正しく識別できてしまえるようにしたいので
- Tips : 大量のデータで事前学習しておく
と
は最小化、
は、最大化するように最適化していく
を入れ、生成した顔画像の酷似を防止している
以上。
【python】raspiでwebカメラとpicameraの両対応コードを実装
モチベーション
カメラをフラグ(PICAM = True )で切り替えられるようにしたい。
[カメラ初期化] cv2.VideoCaptureの置き換え
これはpicameraだと動かないはず。
カメラのイニシャライズをcap取得のwebカメラ、piカメラ両対応する関数を作成。
def initCamera(): cap = None res = False while res is False: if PICAM: cap = picamera.PiCamera() # cap.start_preview() cap.resolution = (640, 480) cap.framerate = 33 cv2.waitKey(1000) res = True else: cap = cv2.VideoCapture(DEVICE_ID) res, _ = cap.read() #pass cv2.waitKey(1000) print('retry ..') return cap
そしてcv2.VideoCaptureを置き換え。
cap = cv2.VideoCapture(device_id) ↓ cap = initCamera()
[画像取得] cap.readの置き換え
こちらもpicameraだと動かない気がする。
picameraはstreamから取ってくるので、次のようなwebカメラpiカメラ両対応の関数を作成する。
def getImage(cap): c_frame = None if PICAM: with picamera.array.PiRGBArray(cap, size=(640, 480)) as stream: c_frame = cap.capture(stream, 'bgr') c_frame = stream.array if c_frame is None: exit else: end_flag, c_frame = cap.read() if end_flag is False or c_frame is None: exit return c_frame
そして置き換え。
img = cap.read() ↓ img = getImage(cap)
以上。
【ipython/jupyter】 ipython notebookの出力データを外部からclearする方法
ipython notebookもしくはjupyter notebookで日頃の作業をしている中で
- 大量のログを出力したままファイルを閉じたり
- ログを出しすぎて処理が重くなり、不用意にterminateしたり
して、次の実行時にipynbファイルの展開が遅くなったり、最悪展開できない、kernelが展開時にterminateすることがある。
その時の対処法をメモ。
やりたいこと=外部から出力カラムを削除
$ pip install nbclean
$ python
> import nbclean
> c = nbclean.clean.NotebookCleaner('./hoge.ipynb')
> c.clear(False, True)
> c.save('./hoge_cleaned.ipynb')ポイントは下記。
> c.clear(False, True)
これの第一引数が入力カラム、第二引数は出力カラムを削除するフラグ。
間違えて、第一引数をTrueにするとコード本体が消える。
詳細はこれ。
https://www.pydoc.io/pypi/nbclean-0.1/autoapi/clean/index.html
追記: それでも開けない場合、ブラウザが未対応なデータを読み込もうとしていたりするので、起動ブラウザを変更してみる。
(個人的にipython notebookを日頃使います)
iPad 9.7 用にpencilケースを100円(格安)で自作する方法

また箸休めですが、今回は最近買ったiPad 9.7 (2018)とApple pencilの為に、100円程でpencilホルダーを作成しました。(ついにこのブログで縫い物を紹介するとは思いませんでした)
最初に断っておくと、私はApple信者ではないので、デザイン性より利便性、カスタマイズ性、重量を重視しております。
なので、「せっかく廉価モデルのiPad 9.7 2018買って費用安く抑えたのに、ケースやらなんやらで4〜5000円とか払うのなんてやだよ!」って人にはオススメです。
別にすごいことはなく誰でも思い付くアイディアではあります。
必要なスキルは、「縫い物ができること」のみです。
(縫い物できなくてもいいですね、そうミシンがあればね)
完成画像
まず完成形はこちら。
iPad、iPadのケースに巻きつけるようなゴムバンドケースを作成しました。

ケースに取り付けるとこんな感じ。

割とサラサラとしたゴムバンドなので上から左にスライドすると、

下から「ぴょこん」と出てくる。(これがかなり便利)

すっ、、、ぴょこん!

作り方
作り方のまとめはこちら。
※慣れの為に、図や絵はApple Pencilで書いてます。(割と書ける)

雑だけどこれが全てである。
大雑把に言うと、20mmゴムバンドを一周半して重なる部分をコの字に縫い付けるだけでできる。
必要な材料と道具
材料
- 20mmゴムバンド (税別100円)
- 刺繍糸
- ボンド
- 爪楊枝 (option)
道具
- 定規
- ハサミ
- 刺繍針
- 待ち針 (option)
手順
スーパーシンプルな3ステップです。
1. 測って

まずゴムバンドを635 [mm] 切り出す (幅はそのまま 20 [mm])


【重要】切り出した両端はボンドをつけて乾かす

解れ防止です。
放置、もしくは、ドライヤーで乾かすとあらキレイ。

2. 折り曲げて

横から見た図は実際にはこんな感じ。(オーバーラップは145 [mm] あればOK)

マチ針か仮縫いで留めておく
3. 縫って(終了)

オーバーラップ部分をコの字に縫い付けていく
(私は左下から縫っていく)

一応、縫う所のイメージ(赤線を上下で繋げる)

縫い付けは端から 2 [mm] ぐらいだといい感じにペンをホールドしてくれる
途中経過はこんな具合

【重要】コの字出口は5 [mm]ほど残しておく(反対側からの写真)

これを残しておくと、スライドした時にここがストッパーになるし、差し込む時の目印にもなるので便利
あとは無心で縫って完成

所感
- ペンケースの保持力もOK(逆さにしても落ちる気がしない)
- スライド感もOK
- めちゃくちゃ便利
- 2週間程使っているが、全く壊れそうにない
ペンキャップ Ver.も作ったがそれも便利だった。
Julia言語とは(備忘録 : 更新版)
twitterなどで目にする機会が増えて、昨日初めてJuliaチュートリアルに参加したので備忘録。(更新版)
チュートリアルで頂いたステッカー↓↓

可愛いね。
Juliaについて
Juliaのライセンス
MITベース
ただし中にあるプロジェクト単位で様々なライセンスがぶら下がっている模様
商用利用はお気をつけて。
julia/LICENSE.md at master · JuliaLang/julia · GitHub
Juliaは何故早い
細かいことはよくわかりませんが、わかっていることだけで
簡単に始める方法
- Juliabox https://juliabox.com/
IDE環境
- Juno IDE http://junolab.org/
- Atomへの導入
margaret-sdpara.blogspot.jp
atom.io
-
- Visual Studio CodeのJuliaの拡張機能
パッケージ
https://pkg.julialang.org/
2018/3/24時点で1749パッケージが登録されている
個人的に、Mamba.jl , BackpropNeuralNet.jlに興味がある
github.com
github.com
他の言語を実行可能
Julia上でgccやclangが実行できるため、C, Fortranのコードを実行可能
Calling C and Fortran Code · The Julia Language
Juliaboxのチュートリアルにもある
Cxx.jiで対話実行できるのでこっちも。
github.com
【python】OCR(tesseract-ocr / pyocr)で賞味期限を読み取る(画像→数列) 【お家IT#19】
本件の実装の一部
motojapan.hateblo.jp
前回の続き
motojapan.hateblo.jp
目次
前回は、バーコード画像から商品情報を取得するところまで進めた。
ただ、商品情報には賞味期限情報は含まれていない。
今回は、OCRを用いて賞味期限を数値、記号情報として取得する。
OCRとは
Optical Character Recognition 光学的文字認識を指す。
紙面に書かれている文字情報を認識してデジタル化する技術であり、書籍や資料を電子化することでデータ圧縮や管理の容易化ができるだけでなく、ソフトウェアと連携してデータ分析なども可能となる。
今回は賞味期限を読み取りたい。
特に、stand-aloneで利用できるtesseract-ocrをpyocrから触ってみる。
(その他のライブラリは次回)
tesseract-ocr / pyocrとは
tesseract-ocrは、OCRエンジンである。
最新α版は、4.00.00alpha。
4系からは、OCR Engine Modeで、LSTMが選択できるようになっている。
(ただし、下記pyocrからは、Mode設定がサポートされていない模様で、LSTMは今回は試せなった)※2017/10時点
github.com
pyocrは、tesseract-ocrをpythonから操作する為のWrapperである。
かなり感単に操作が可能となっている。
インストール
tesseract-ocrをインストール & チェック
#install $ sudo apt-get install tesseract-ocr #check $ tesseract -v tesseract 3.03 leptonica-1.71 libgif 4.1.6(?) : libjpeg 6b : libpng 1.2.50 : libtiff 4.0.3 : zlib 1.2.8 : libwebp 0.4.1 : libopenjp2 2.1.0
pyocrをインストール & チェック
#install $ pip install pyocr #check $ python >>> import pyocr >>> pyocr.get_available_tools() [<module 'pyocr.tesseract' from '/usr/local/lib/python2.7/dist-packages/pyocr/tesseract.pyc'>]
使い方と実装
pyocr.builders
pyocr.buildersには次の5つの使えそうなBuilderがある。
| TextBuilder | 文字列を認識 | |
| WordBoxBuilder | 単語単位で文字認識 + BoundingBox | |
| LineBoxBuilder | 行単位で文字認識 + BoundingBox | |
| DigitBuilder | 数字 / 記号を認識 | 今回はこれを採用 |
| DigitLineBoxBuilder | 数字 / 記号を認識 + BoundingBox |
今回は、撮影枠を準備しているので、DigitBuilderを採用。
tesseract_layout (pagesegmode)
tesseract_layoutを設定しているが、ここは次のpagesegmodeの番号と対応している。
ここの設定でかなり精度は変わる。
デフォルト設定は、tesseract_layout=3。
今回は、tesseract_layout=6で、単一ブロックとして認識。
OSDとは、On Screen Display? サブタイトルなどの認識に利用するらしい。
pagesegmode values are: 0 = Orientation and script detection (OSD) only. 1 = Automatic page segmentation with OSD. 2 = Automatic page segmentation, but no OSD, or OCR 3 = Fully automatic page segmentation, but no OSD. (Default) 4 = Assume a single column of text of variable sizes. 5 = Assume a single uniform block of vertically aligned text. 6 = Assume a single uniform block of text. 7 = Treat the image as a single text line. 8 = Treat the image as a single word. 9 = Treat the image as a single word in a circle. 10 = Treat the image as a single character.
実装
import time import pyocr from PIL import Image import pyocr.builders #img : PIL image def get_digit_ocr_info(img): result = None start_time = time.time() print('******** start convert_image_to_deadline *********') width, height=img.size tools = pyocr.get_available_tools() tool = tools[0] print(tool) langs = tool.get_available_languages() print("support langs: %s" % ", ".join(langs)) #lang = langs[0] lang = 'eng' #言語設定で、「英語」を選択 digit_txt = tool.image_to_string( img, lang=lang, builder=pyocr.builders.DigitBuilder(tesseract_layout=6) ) print('DigitBuilder', digit_txt) print('******** end convert_image_to_deadline *********') return digit_txt
結果
色々なパターンを12件ほど評価。
入力画像 |
tesseract+pyocr |
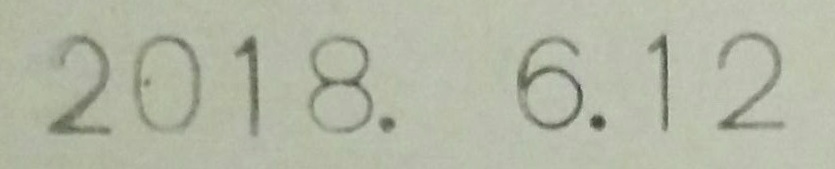 |
2018. 6.12 |
 |
18.12.31 |
 |
2018. 5. 7 |
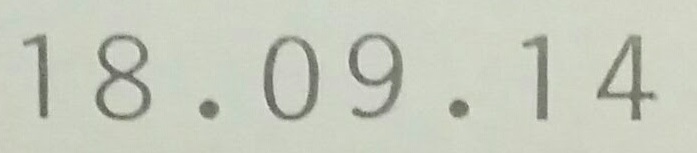 |
18.09.14 |
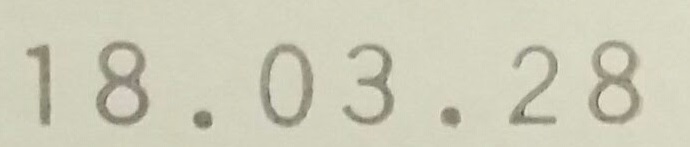 |
18.03.28 |
 |
4 13 11-13 . . 3 |
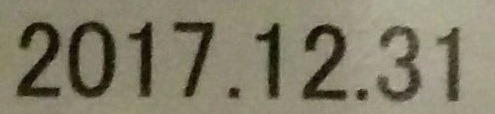 |
2017.12 31 |
 |
4 21 3 |
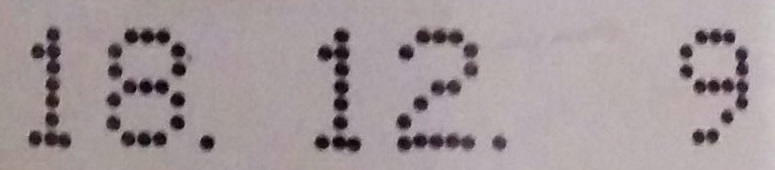 |
13. 1-7 |
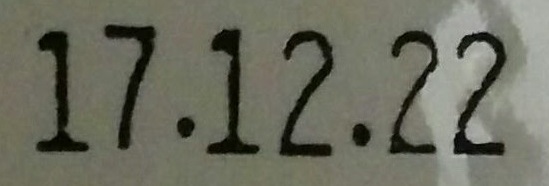 |
17.12.22 |
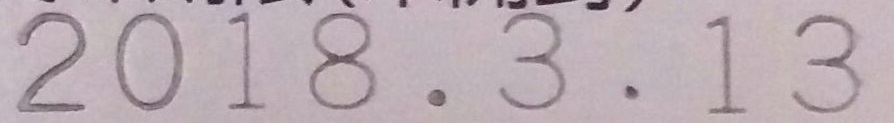 |
20-178.... 3 13 |
 |
2311 8.13 |
200 x 60 の画像に対して、処理速度は、2 - 3 [s]程度。結構時間がかかる。
上手くいくものもあれば、厳しいものもある。
特に、太い文字、判で刻印されたシャープな数字はかなりいい感じだが、無駄な文字が含まれている画像、暗い画像、ドット記載されている数字が上手く読み取れていない印象。
以上。
これでシステム全体の開発は終わり。
また何か作る予定です。
今回触れなかった他のOCRライブラリの話もそのうち纏めたい。
【python】Yahoo Web APIでバーコード情報(JAN)から商品名を読み出す(数列→商品情報) 【お家IT#18】
本件の実装の一部
motojapan.hateblo.jp
前回の続き
motojapan.hateblo.jp
目次
前回は画像からバーコード情報(数列)を取得した。
今回はこの情報から、商品情報を取得する。
取得方法のアイディア
実際このバーコード情報から商品名を求める方法はいくつかある。
今回はWebAPIを中心に話を進めるが折角なのでスクレイピングも少しみてみる。
1.スクレイピングする方法
例えば、JANコード「9000009984074」に対応するのは、お馴染み「クリスタルカイザー」という飲料水。
これを検索にかけてみるとこうなる。
BeautifulSoup4 をインストール
$ apt-cache search beautifulsoup $ sudo apt-get install python3-bs4
実装
python3.x系で実装するとこんな感じ
import urllib.request from bs4 import BeautifulSoup headers = { "User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0", } request = urllib.request.Request(url='https://www.google.co.jp/search?q=9000009984074+jan', headers=headers) response = urllib.request.urlopen(request) html = BeautifulSoup(response) print(html)

2.WebAPIで検索する方法(種類)
脱線したがこちらが本筋。
WebAPIでバーコード情報から商品名を求められるメジャーどころは下記。
Product Advertising API (Amazon Web Services)
楽天商品検索API (Rakuten Developers)
Yahoo! Developer Networksを使ってみる
今回はまず手軽にやってみたいので、Yahoo! APIにした。
さらに、Yahoo! Developer Networksを使うモチベーションは、Yahoo!が提供する地図や気象情報などの多種多様なサービスがWebAPIから扱えるという点もあったので、今回登録してみた。
次の前提は把握していたほうが話がスムーズ。
- Yahoo! Developer Networksは、ディベロッパー(アカウント)登録が必要である
- 「アプリケーション」という単位で管理している
- 1アカウント当たり、10個までのアプリケーションを登録できる
- クエリ数は、アプリケーション通算の総カウントで計算される
- API別に上限がある
登録
ディベロッパー登録
まずディベロッパー登録を下記から行う。
Yahoo! JAPAN ID登録 - Yahoo! JAPAN
gmailでも登録できる。
アプリケーション登録
「アプリケーション管理」から「新しいアプリケーションを開発」を選択。

アプリケーションの種類を選択し、他の入力情報を埋める。

「クライアントサイド」を選択する場合はこんな感じ。
クライアントID取得
アプリケーションを登録後、「デベロッパーネットワークトップ」>「アプリケーションの管理」>「アプリケーションの詳細」から、「Client ID」をメモする。

ここでメモしたIDを、
インストール & 実装
必要モジュールをインストール
$ pip install beautifulsoup4
単なるWebAPIとして扱えるので「スクレイピングする方法」と似たように簡単だが今度はpython2.7系で実装するとこんな感じ。
import urllib from bs4 import BeautifulSoup // code : バーコード情報 def code_to_product_info(code): print('*********** start product_info ************') start_time = time.time() product_info = None client_id = '<client_id>' url = 'http://shopping.yahooapis.jp/ShoppingWebService/V1/itemSearch?appid={0}&jan={1}'.format(client_id, code) response = urllib.urlopen(url).read() soup = BeautifulSoup(response) res = soup.find_all('name') // nameタグを取得 //ここから超雑 if len(res) > 0: product_info = res[0] print 'proc_time {0:f} [ms] '.format((time.time() - start_time) * 1000) return product_info print('*********** end product_info ************')
結果
クリスタルガイザー ミネラルウォーター 500ml×48本 並行輸入品 代引不可

処理速度は50-150[ms]程度。(通信状況によって揺らぐ)
以上。
ここまでで、画像から商品名(食品名)を検索するモジュールができた。
次回からは、OCRを用いて画像から賞味期限を取得するモジュールの話を進めたい。