【python】OCR(tesseract-ocr / pyocr)で賞味期限を読み取る(画像→数列) 【お家IT#19】
本件の実装の一部
motojapan.hateblo.jp
前回の続き
motojapan.hateblo.jp
目次
前回は、バーコード画像から商品情報を取得するところまで進めた。
ただ、商品情報には賞味期限情報は含まれていない。
今回は、OCRを用いて賞味期限を数値、記号情報として取得する。
OCRとは
Optical Character Recognition 光学的文字認識を指す。
紙面に書かれている文字情報を認識してデジタル化する技術であり、書籍や資料を電子化することでデータ圧縮や管理の容易化ができるだけでなく、ソフトウェアと連携してデータ分析なども可能となる。
今回は賞味期限を読み取りたい。
特に、stand-aloneで利用できるtesseract-ocrをpyocrから触ってみる。
(その他のライブラリは次回)
tesseract-ocr / pyocrとは
tesseract-ocrは、OCRエンジンである。
最新α版は、4.00.00alpha。
4系からは、OCR Engine Modeで、LSTMが選択できるようになっている。
(ただし、下記pyocrからは、Mode設定がサポートされていない模様で、LSTMは今回は試せなった)※2017/10時点
github.com
pyocrは、tesseract-ocrをpythonから操作する為のWrapperである。
かなり感単に操作が可能となっている。
インストール
tesseract-ocrをインストール & チェック
#install $ sudo apt-get install tesseract-ocr #check $ tesseract -v tesseract 3.03 leptonica-1.71 libgif 4.1.6(?) : libjpeg 6b : libpng 1.2.50 : libtiff 4.0.3 : zlib 1.2.8 : libwebp 0.4.1 : libopenjp2 2.1.0
pyocrをインストール & チェック
#install $ pip install pyocr #check $ python >>> import pyocr >>> pyocr.get_available_tools() [<module 'pyocr.tesseract' from '/usr/local/lib/python2.7/dist-packages/pyocr/tesseract.pyc'>]
使い方と実装
pyocr.builders
pyocr.buildersには次の5つの使えそうなBuilderがある。
| TextBuilder | 文字列を認識 | |
| WordBoxBuilder | 単語単位で文字認識 + BoundingBox | |
| LineBoxBuilder | 行単位で文字認識 + BoundingBox | |
| DigitBuilder | 数字 / 記号を認識 | 今回はこれを採用 |
| DigitLineBoxBuilder | 数字 / 記号を認識 + BoundingBox |
今回は、撮影枠を準備しているので、DigitBuilderを採用。
tesseract_layout (pagesegmode)
tesseract_layoutを設定しているが、ここは次のpagesegmodeの番号と対応している。
ここの設定でかなり精度は変わる。
デフォルト設定は、tesseract_layout=3。
今回は、tesseract_layout=6で、単一ブロックとして認識。
OSDとは、On Screen Display? サブタイトルなどの認識に利用するらしい。
pagesegmode values are: 0 = Orientation and script detection (OSD) only. 1 = Automatic page segmentation with OSD. 2 = Automatic page segmentation, but no OSD, or OCR 3 = Fully automatic page segmentation, but no OSD. (Default) 4 = Assume a single column of text of variable sizes. 5 = Assume a single uniform block of vertically aligned text. 6 = Assume a single uniform block of text. 7 = Treat the image as a single text line. 8 = Treat the image as a single word. 9 = Treat the image as a single word in a circle. 10 = Treat the image as a single character.
実装
import time import pyocr from PIL import Image import pyocr.builders #img : PIL image def get_digit_ocr_info(img): result = None start_time = time.time() print('******** start convert_image_to_deadline *********') width, height=img.size tools = pyocr.get_available_tools() tool = tools[0] print(tool) langs = tool.get_available_languages() print("support langs: %s" % ", ".join(langs)) #lang = langs[0] lang = 'eng' #言語設定で、「英語」を選択 digit_txt = tool.image_to_string( img, lang=lang, builder=pyocr.builders.DigitBuilder(tesseract_layout=6) ) print('DigitBuilder', digit_txt) print('******** end convert_image_to_deadline *********') return digit_txt
結果
色々なパターンを12件ほど評価。
入力画像 |
tesseract+pyocr |
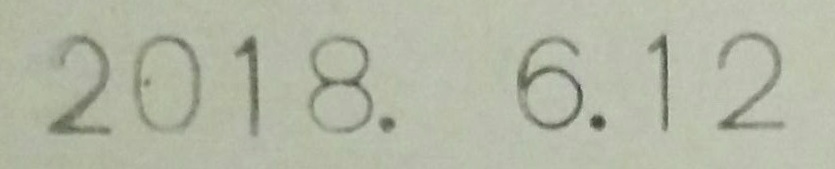 |
2018. 6.12 |
 |
18.12.31 |
 |
2018. 5. 7 |
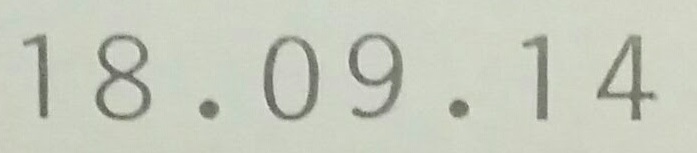 |
18.09.14 |
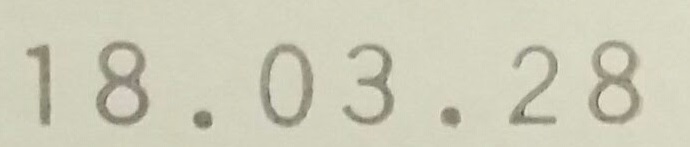 |
18.03.28 |
 |
4 13 11-13 . . 3 |
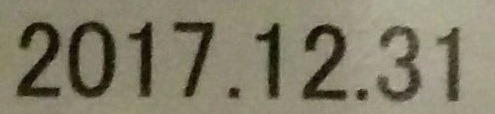 |
2017.12 31 |
 |
4 21 3 |
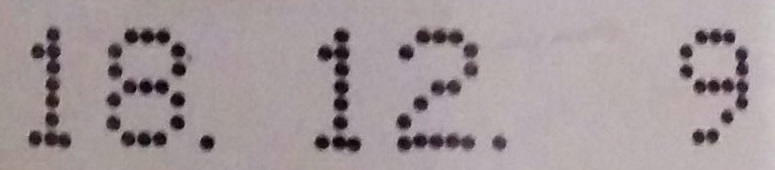 |
13. 1-7 |
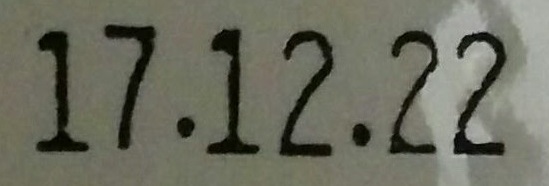 |
17.12.22 |
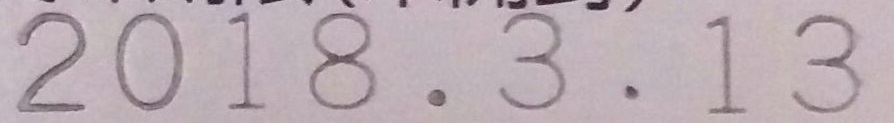 |
20-178.... 3 13 |
 |
2311 8.13 |
200 x 60 の画像に対して、処理速度は、2 - 3 [s]程度。結構時間がかかる。
上手くいくものもあれば、厳しいものもある。
特に、太い文字、判で刻印されたシャープな数字はかなりいい感じだが、無駄な文字が含まれている画像、暗い画像、ドット記載されている数字が上手く読み取れていない印象。
以上。
これでシステム全体の開発は終わり。
また何か作る予定です。
今回触れなかった他のOCRライブラリの話もそのうち纏めたい。